近年来,disaggregation架构在大型数据中心中开始得到应用,在此架构下,包括内存、处理器、硬盘等资源不再像传统模式下分布在各个节点上,一个节点只专注于提供单一类型的资源,节点之间使用高速网络互联,应用需要使用某种资源时按需前往对应节点上获取该类资源。这样的架构主要有如下三点优势:
- 提升资源利用率:将进程与资源解耦并允许进程访问远端资源,有利于全局的调度器更好地利用资源;
- 提升容错性:服务器故障仅仅会影响单一资源,不会对其他资源的availibility造成影响;
- 提升弹性:便于在负载变化的情况下动态扩容。另外专注于提供某一类资源的服务器有利于新型硬件的适配。1
本文讨论了一种常见的disaggration模式下的应用部署方式:一台处理器资源服务器运行程序,数据则存储于远端内存资源服务器中,当需要使用内存中的数据时,程序从远端使用RDMA网络将远端内存读取放入本地缓存中进行运算。在这种场景下,应用的性能高度依赖于内存的时空局部性,因为RDMA网络尽管提供了有效的访问远端服务器数据的能力,但是延迟仍然比访问本地内存高约两个数量级。现有大量工作致力于优化上述场景中的远端数据访问,但这些工作多数关注于底层,缺乏运行时的语义。对于managed languages,提升局部性主要面临了两项挑战:资源回收(GC)时通常涉及图遍历,图遍历的局部性较差;大量使用面向对象的数据结构,引入了较多指针的操作。
本文提出Semeru,Semeru是一个分布式的Java虚拟机,它可以在内存分离的环境中运行管理语言程序,提高云应用的性能。它的核心思想是将Java堆分为两个部分:一个位于CPU服务器上的热区,和一个位于内存服务器上的冷区。它主要的insight是一部分GC的工作可以被迁移到内存节点上进行运算,由于GC是内存敏感型的任务,因此内存节点上的计算资源足以应付GC工作。另外将有较高概率同时访问到的对象放在同一内存节点也有利于提升局部性。Semeru利用了三个技术来实现这个目标:
- 通用的Java堆:它提供了一个跨CPU和内存服务器的虚拟内存的统一抽象,使得任何遗留的程序都可以不用修改地运行。它使用了一种新颖的地址转换机制,将虚拟地址映射到物理地址,从而实现了透明的内存访问。
- 分布式的垃圾回收器:它将对象追踪的工作卸载到内存服务器,使得追踪更接近数据。它使用了一种基于并发标记清除的算法,将对象分为四种状态:本地,远程,迁移,和死亡。它通过一种轻量级的协议,维护了对象状态的一致性,从而实现了高效的垃圾回收。
- 内核交换系统:它与运行时协作,高效地交换页面数据。它使用了一种基于优先级的策略,根据对象的访问频率和远程性,动态地调整页面的位置。它通过一种基于批处理的机制,减少了网络传输的开销,从而实现了高效的页面交换。
内存抽象
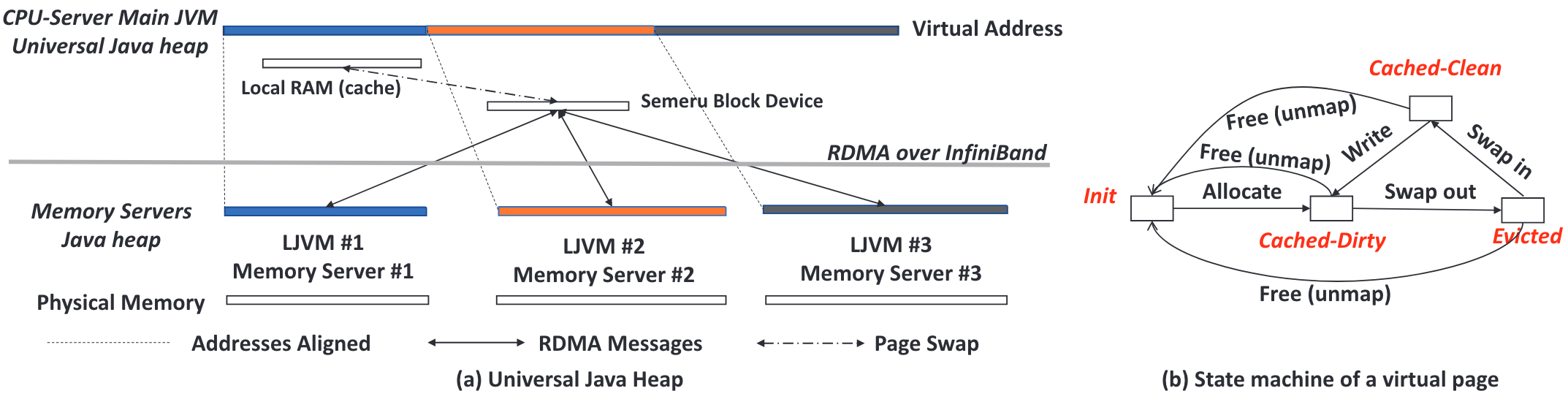
Semeru提出了UJH(Universal Java Heap)的抽象,如下图所示。处理器节点能够访问一大段连续的内存空间,而内存节点则分别存储了堆上相互不相交的一部分内存。如果处理器节点访问到UJH中的地址发生缺页时,block layer会负责通过RDMA读取对应内存节点的内存并放入本地缓存中。另外Semeru实现了一套简单的类似于DSM的协议用于保持处理器节点和内存节点的缓存一致性。
分布式GC方法
Semeru实现了一套分布式的GC方法,来确定哪些GC工作可以被迁移到内存节点上运行、应当如何迁移。该GC方法分为两步:MSCT(Memory Server Concurrent Tracing)和CSSC(CPU Server Stop-The-World Collection)。首先,MSCT是指在处理器节点mutator在运行时,内存节点不断从本地存活的根对象开始通过指针迭代遍历对象,形成存活对象的闭包。这样设计的优势在于该过程中内存节点只会访问本地的内存,避免跨界点访问的开销。另外由于MSCT过程是只读的,因此可以和mutator完全并行执行。
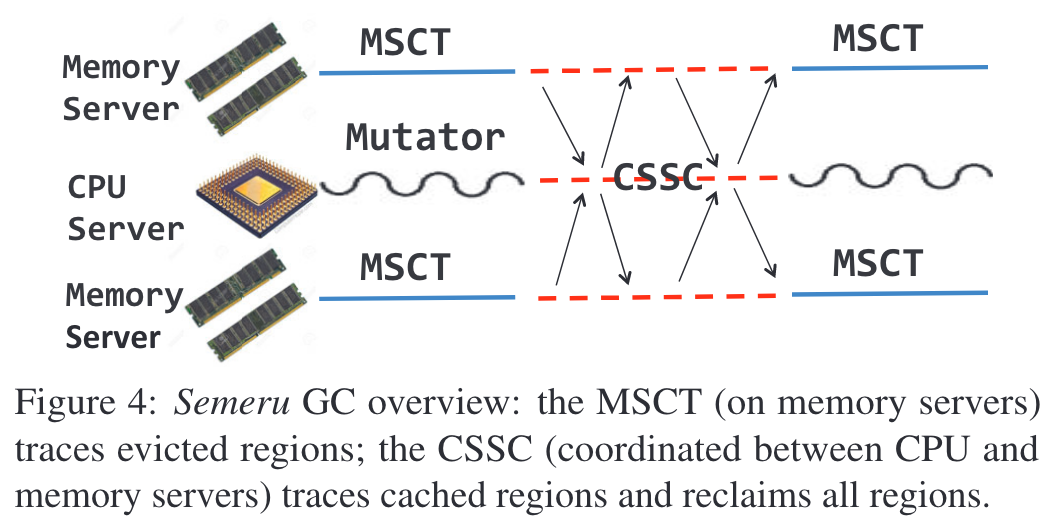
接下来,在真正需要触发GC时,处理器节点和内存节点均会暂停运行,进入CSSC阶段。该阶段处理器节点和内存节点将协同完成GC工作,协议如下图所示。该算法较为复杂,大致可以分为两个部分:首先,处理器节点将决定内存节点上的哪些区域需要被回收,并将相关信息发送至内存节点,内存节点将会把其中存活的对象(在MSCT中已经确定)拷贝到新的内存区域中;其次,在内存节点回收资源的过程时,处理器节点同时对位于本地缓存中的部分内存区域进行回收,这些被缓存的内存区域不在内存节点上,因此没有在MSCT过程中进行分析,所以需要处理器节点计算这些区域中的存活对象闭包,最后将对象的元数据信息更新至内存节点。

Result
Semeru与RD、NVMe两种配置进行对比,RD表示使用处理器本地的Ramdisk模拟远端内存,NVMe则使用远端的内存,RD和NVMe两种配置均使用原生OpenJDK的实现。另一自变量未本地缓存的大小,分别为总内存大小的50%和25%,Baseline为所有远端内存均能够缓存在本地的性能(即100% Cache)。
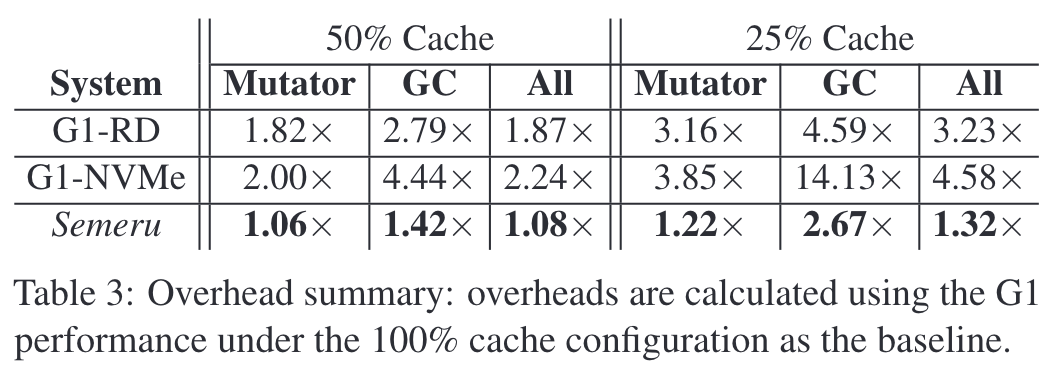
即使在所有内存均在本地的情况下,RD配置仍然引入了额外0.87到2.23倍的性能开销,因为原生的GC算法引入了较多在JDK和Ramdisk中相互拷贝的数据。当内存在远端时,原生JDK额外开销更大。与此同时,Semeru通过分布式的GC算法提升了局部性,使得性能开销仅有8%至32%。