修改xv6的内核接口,构建状态机规范和声明式规范以支持SMT(Satisfiability Modulo Theories)求解器来进行验证。通过有限化内核接口,使用硬件虚拟化简化虚拟内存推理,并在LLVM IR级别工作,以避免对C语义进行建模,从而实现了"一键验证"。
程序员使用Python编写两种规范来指定系统调用的期望行为:详细的状态机规范和更高级的声明式规范。两种规范都用Python表达,并使用Z3 SMT求解器进行验证。程序员使用C实现系统调用。验证器将Python规范和C编译成的LLVM IR实现转化为SMT查询,并调用Z3进行验证。验证后的代码与未验证的(可信任的)代码链接,生成最终的内核映像。
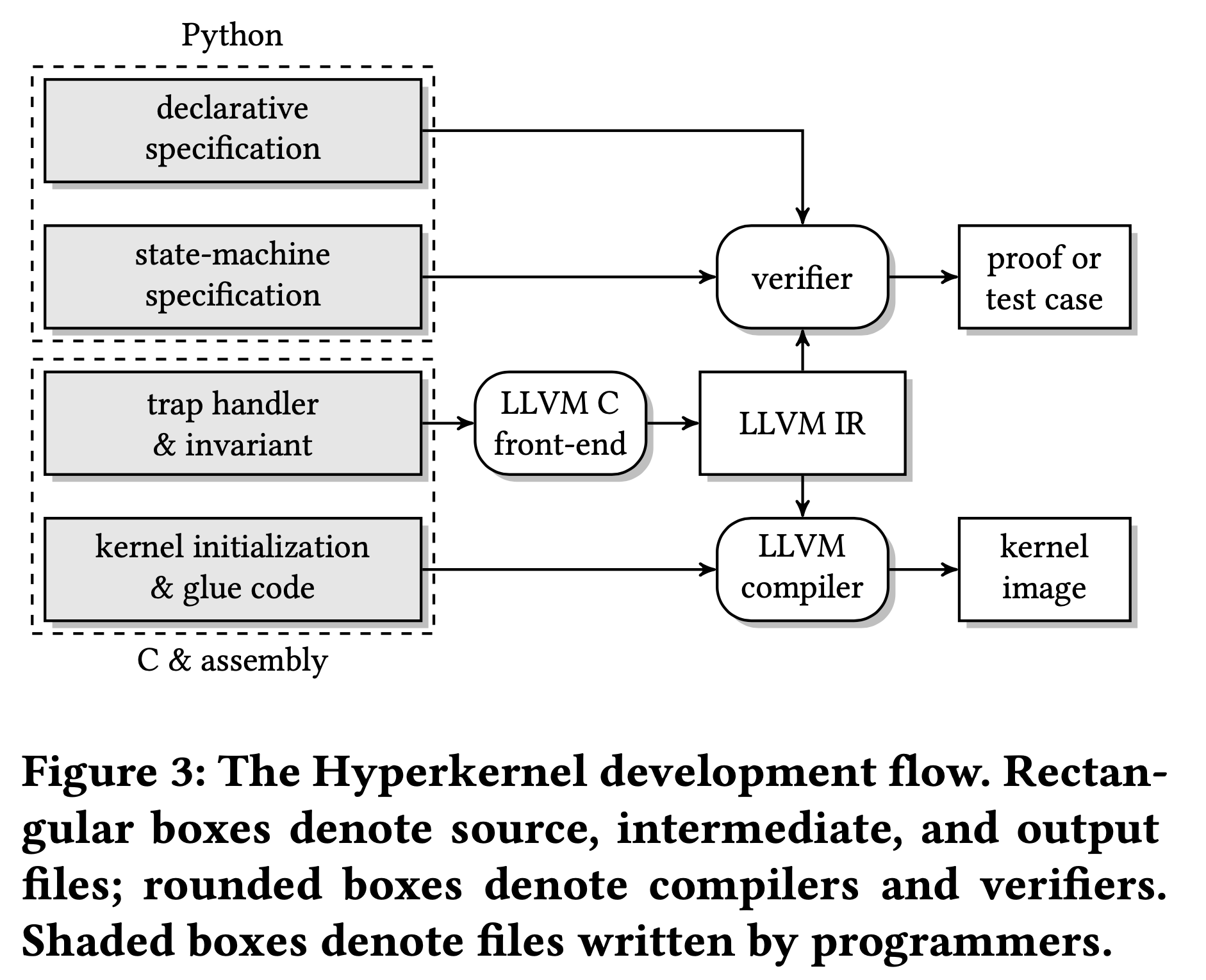
Hyperkernel 验证面临的挑战与解决办法
挑战一
内核接口的设计需要在可用性和自动化验证之间取得平衡。内核需要提供丰富的抽象来保证用户程序的正确性,但接口也必须容易实现并验证。
解决办法:设计了有限的内核接口,避免了无界的循环和递归。
在Unix设计中,每个进程都有一个文件描述符表,每个槽位都指向系统范围内的文件表。文件表维护每个条目的引用计数器,以正确管理资源。
dup(oldfd)的 POSIX 语义是“创建oldfd的副本,使用最小未使用的文件描述符作为新描述符”。例如,在进程j中调用dup(0)将返回FD 1,引用文件表条目 4,并将该条目的引用计数增加到 3。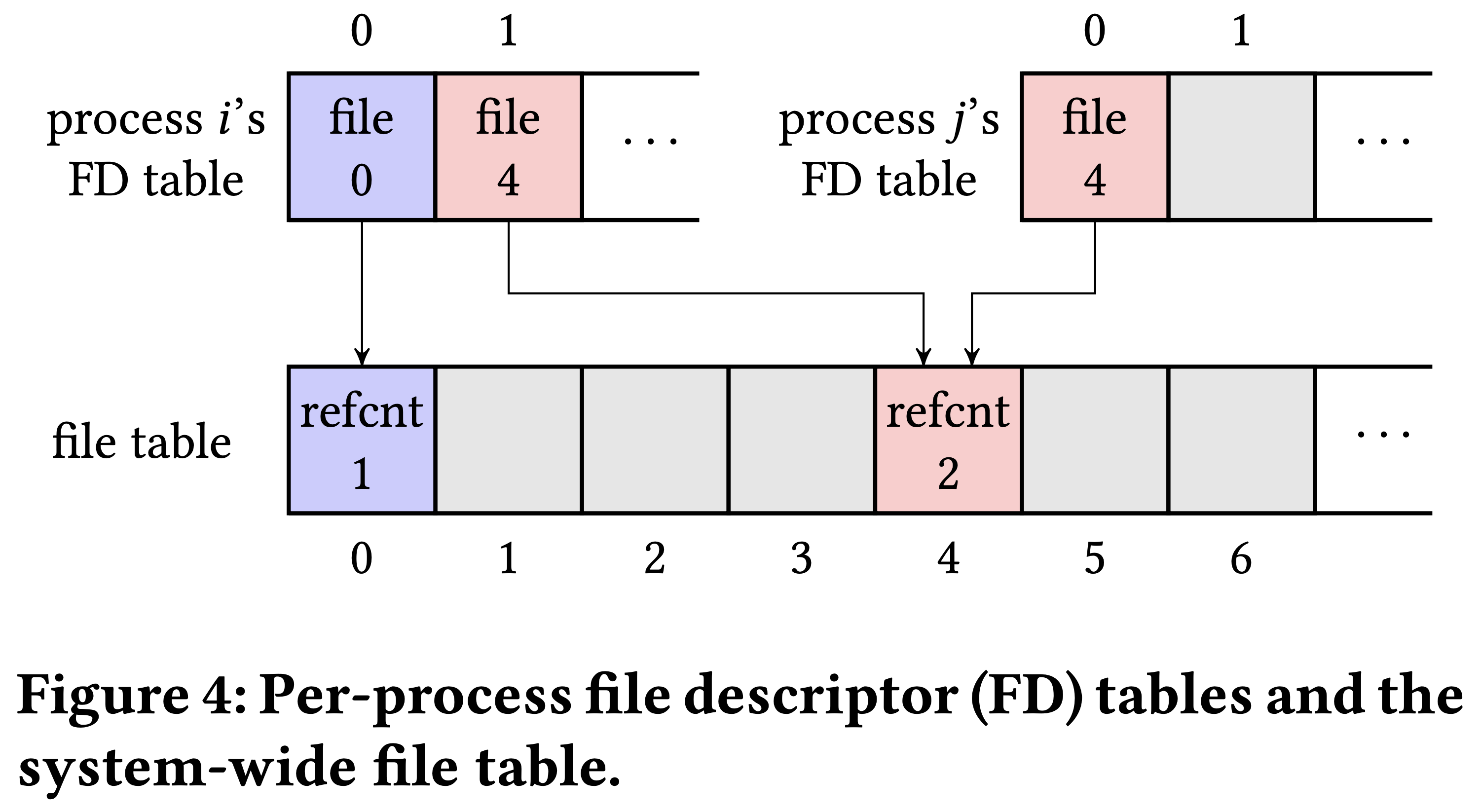
dup接口的POSIX语义是非有限的。因为最小FD需要内核检查每个小于新选择的FD的slot是否已经被占用。因此,分配最小FD需要一个随着FD表大小增长的跟踪,即跟踪长度不能被一个独立于系统参数的小常数所限制。缺乏有限界意味着dup的验证时间会随着FD表的大小增加而增加。Hyperkernel通过将POSIX接口改为
dup(oldfd, newfd)来进行有限化处理,这要求用户空间选择一个新的FD值。为了实现这个接口,内核只需检查给定的newfd是否未使用。这个检查只需要O(1),与FD表的大小无关。因此,该接口是有限的,可以进行可扩展的验证,避免了路径爆炸。
挑战二
由于内核和用户空间共享一个虚拟地址空间,需要处理内核代码中虚拟地址到物理地址的转换,增加了验证难度。在验证中同时处理中断、并发和外设I/O也是一个大挑战。
解决办法:
内核在禁用中断的情况下执行陷阱处理程序,直到返回用户空间(再次陷入内核)之前,中断被推迟。通过这样做,每个陷阱处理程序都在内核中完整运行。
使用硬件虚拟化技术给内核和用户空间分配独立的页表,内核使用恒等映射简化了虚拟地址管理。
内核通过将DMA限制在专用内存区域来隔离设备对内存的异步修改,从而实现对其影响的隔离。这一机制的实现是通过 Intel 的 VT-d Protected Memory Regions 或 AMD 的 Device Exclusion Vector 来实现的。
挑战三
内核使用C语言实现,而C语言中像指针算术和内存访问这样的低级操作,以及未定义行为,会使形式化验证变得非常困难。
解决办法:在LLVM IR而不是C源代码级别进行验证,减少了对C语言语义的建模。
挑战四
许多POSIX系统调用如fork和mmap的语义都是非有限的,不易用SMT表达式表示和验证。
解决办法:将复杂系统调用像fork/exec分解为多个细粒度的原语系统调用。只在内核实现这些原语系统调用,确保隔离性。复杂逻辑在用户态实现。
挑战五
保证规范的正确性,避免规范本身存在bug也不容易。
解决办法:提出了两级规范,通过一致性检查增强对规范的信心。
程序员通过提供一个状态机规范来描述内核的期望行为,该规范包括抽象内核状态的定义以及基于抽象状态转换的陷阱处理程序(例如系统调用)的定义。除了状态机规范,程序员还可以选择提供高级属性的声明式规范,以确保状态机规范满足这些高级属性。Hyperkernel验证器将检查这些高级属性是否确实满足,从而增加程序员对状态机规范正确性的信心。
抽象内核状态
使用固定宽度整数和映射来定义抽象内核状态:
2
3
4
5
6class AbstractKernelState(object):
current = PidT()
proc_fd_table = Map((PidT, FdT), FileT)
proc_nr_fds = RefcntMap(PidT, SizeT)
file_nr_fds = RefcntMap(FileT, SizeT)
...current表示当前运行的进程的 PID;
proc_fd_table表示每个进程的文件描述符表,将 PID 和 FD 映射到文件;
proc_nr_fds映射进程的 PID 到该进程使用的文件描述符数量;
file_nr_fds映射文件到所有进程引用该文件的文件描述符总数量。状态机规范
系统调用的规范通常遵循一个模式:验证系统调用参数,如果验证通过,则将内核转换到下一个状态并返回零;否则,系统调用返回错误代码,内核状态不会改变。每个系统调用规范都提供验证条件和新状态,以
dup为例:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24def spec_dup(state, oldfd, newfd):
# state is an instance of AbstractKernelState
pid = state.current
# validation condition for system call arguments
valid = And(
# oldfd is in [0, NR_FDS)
oldfd >= 0, oldfd < NR_FDS,
# oldfd refers to an open file
state.proc_fd_table(pid, oldfd) < NR_FILES,
# newfd is in [0, NR_FDS)
newfd >= 0, newfd < NR_FDS,
# newfd does not refer to an open file
state.proc_fd_table(pid, newfd) >= NR_FILES,
)
# make the new state based on the current state
new_state = state.copy()
f = state.proc_fd_table(pid, oldfd)
# newfd refers to the same file as oldfd
new_state.proc_fd_table[pid, newfd] = f
# bump the FD counter for the current process
new_state.proc_nr_fds(pid).inc(newfd)
# bump the counter in the file table
new_state.file_nr_fds(f).inc(pid, newfd)
return valid, new_state正常情况下还有spec中错误代码,但此处省略了。
声明式规范
状态机规范是一个抽象的规范,不包含C语言中的未定义行为,也不涉及实现细节,比如内存中的数据布局。但是在编写状态机规范时,程序员仍然需要注意一些细节,比如在指定
dup时正确修改文件表中的引用计数。为了提高对状态机规范正确性的信心,还开发了一个更高级的声明式规范,这个规范以一系列交叉属性的合取形式呈现,这些属性适用于所有陷阱处理程序。考虑 high-level 的文件表中的引用计数正确性属性:如果文件的引用计数为零,则不能有任何文件描述符指向该文件。(high-level 我理解是跳出了单个 interface 的范围,普遍适用的规范,all trap handlers should follow the property)
声明如下:
上述仅关注于引用计数为零时不能有指向其的文件描述符。更一般的,每个陷阱处理程序都应该维护一个文件的引用计数,该计数等于引用该文件的每个进程文件描述符的总数。
ForAll([f, pid, fd], Implies(file_nr_fds(f) == 0, proc_fd_table(pid, fd) != f))对于引用计数,即使状态机规范和实现都无法正确更新引用计数器,声明式规范也会暴露出错误。
挑战六
验证不能覆盖内核的全部代码,例如内核中的表示不变量(representation invariant)。
解决办法:
内核会显式地检查来自用户空间的值(例如系统调用参数),因为这些值是不受信任的。但通常情况下,内核内部的值的有效性是隐式假设的。例如,考虑全局变量
current,它存储了当前运行进程的PID。dup系统调用的实现使用current来索引procs数组。为了检查(而不是假设)此访问不会导致缓冲区溢出,Hyperkernel 有两个选择:动态检查或静态检查。动态检查在
dup(以及使用current的其他系统调用)中插入以下代码进行测试:
if (current > 0 && current < NR_PROCS) { ... }
缺点是会增加内核的大小并浪费 CPU 时间。静态检查是在验证时进行检查。程序员编写了与
current的相同范围检查,但在一个特殊的check_rep_invariant()函数中,该函数描述了内核数据结构的表示不变性。验证器将尝试证明每个陷阱处理程序都维护表示不变性。
规范
使用SMT求解器的优点是,如果验证失败,它能够生成一个测试用例,有助于定位和修复错误。验证器会生成一个具体的测试用例,包括内核状态和系统调用参数,以描述如何触发错误。如果两者之间存在不一致,验证器会显示违规情况。
验证
Hyperkernel的验证主要证明了两个定理: 
Theorem 1: REFINEMENT
验证器会对每个陷阱处理程序:
- 将内核的 C 实现编译成 LLVM IR;
- 程序员提供的等价约束,关联实现和规范,例如:
左侧辅助函数1
llvm_global('@current') == state.currentllvm_global在 LLVM IR 中查找一个名为current的符号(@表示 LLVM 中的全局符号),右侧表示抽象状态中的当前 PID; - 符号执行 IR,翻译成 SMT 表达式;
- 将 Python 编写的状态机规范翻译成 SMT 表达式;
- 将上述输入送给 Z3,检查它们是否在每个状态转换中同步移动来证明是否满足定理1。
Theorem 2: CROSSCUTTING
验证器将Python编写的状态机规范和声明规范转换为SMT,并在每个状态转换后检查声明规范是否成立,以证明定理2的正确性。
验证失败
如果验证器无法证明两个定理,它可以发现以下两类错误:
- 在实现中的错误:未定义行为或违反状态机规范的错误。
- 在状态机规范中的错误:违反声明式规范的错误。
在这些情况下,验证器会尝试从 Z3 反例中生成具体的测试用例,以帮助调试问题。例如,如果程序员忘记验证 dup 中的系统调用参数 oldfd,验证器会输出一个堆栈跟踪,以及导致 FD 表中越界访问的具体 oldfd 值。
另一个例子是,如果程序员忘记在 dup 实现中增加文件表中的引用计数,验证器会突出显示在状态机规范中被违反的子句,并提供一个简化的解释。这个解释描述了在系统调用之前和之后的内核状态以及规范的状态。通常情况下,规范和实现在系统调用之前是等价的,但是在系统调用之后,规范中的计数器已经正确更新,而实现中的计数器保持不变,这破坏了等价性,因此证明失败。
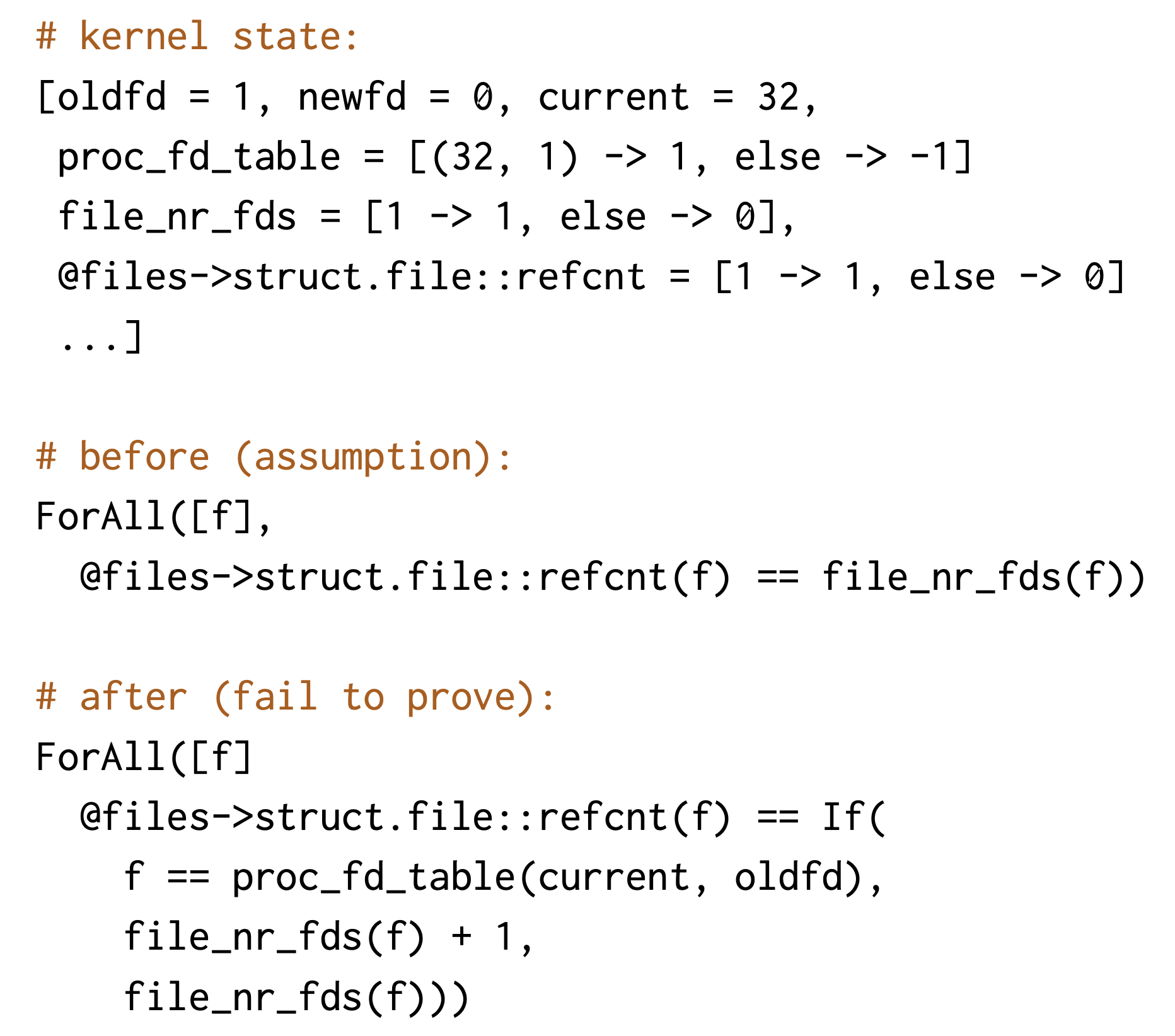
这个输出表明,在进程PID 32中调用dupfd(1, 0)会触发一个bug。系统调用之前的内核状态是:PID 32是当前运行的进程;它的FD 1指向文件1(引用计数为1);其他FD和文件表项为空。两个ForAll语句分别突出了系统调用之前和之后的有问题的状态。在调用之前,规范和实现状态是等价的。在系统调用之后,规范中的计数器被正确更新(即文件1的计数器file_nr_fds增加了1);然而,在实现中计数器保持不变(即@files->struct.file::refcnt),这破坏了等价函数,因此证明失败。
文中提到的两个定理在 Z3 无法找到任何反例时成立。 定理1保证已验证的内核实现部分没有低级别错误,例如缓冲区溢出、除零和空指针解引用。此外,它还保证功能正确性,即每个系统调用的实现都满足状态机规范。 定理2保证状态机规范与声明式规范相符。
需要注意的是,这两个定理并不保证内核初始化、粘合代码或生成的内核二进制的正确性。
验证器
验证器的任务是验证内核的正确性,这包括两个主要的正确性定理。
内核行为建模: 验证器将内核的执行行为建模为一个状态机。在此模型中,状态迁移可以由陷阱处理或用户空间执行(不陷入内核)触发。Hyperkernel 中的陷阱处理是原子性的,这种原子性简化了验证过程,允许验证器独立地分析每个陷阱处理程序。
原子性保证: 即使在单处理器系统中,为了确保陷阱处理程序的原子执行,Hyperkernel 需要处理来自I/O设备的并发问题,如中断和直接内存访问(DMA)。它通过禁用中断来实现原子性,延迟中断处理,直到执行返回用户空间。此外,为了隔离DMA的效果,内核将DMA限制在专用内存区域(称为DMA页面),并将这种隔离实现为在引导时配置的机制。DMA页面被视为易变的,读取DMA页面的内存将返回任意值。
内核正确性的定义与验证: 内核的正确性以状态机refinement的形式定义。Z3验证器通过验证其否定是不可满足的来验证其正确性。如果找到反例,验证器会构建一个测试用例。


LLVM IR 的处理: 验证器将 LLVM IR 代码作为验证目标,通过符号执行来构建 SMT 表达式。它会处理 LLVM IR 中的未定义行为,并将 LLVM IR 中的指令映射到 SMT 表达式。对于易变内存访问(如 DMA 页面),验证器会生成适当的 SMT 表达式。验证器允许程序员提供内联汇编代码的抽象模型,以简化验证过程。这个模型是被信任而不是验证的,它通常用于模拟特定的硬件行为。
编码交叉属性: 交叉属性是在声明性规范中定义的属性,它们描述了内核资源的管理方式和约束。这些属性通常包括:
exclusive ownership:某些资源只能由一个对象独占拥有;
reference-counted shared ownership:共享资源的引用计数必须与引用该资源的对象数量相匹配。
对于exclusive ownership,如每个进程具有自己独立的地址空间,资源必须被独占拥有的属性,验证器采用以下编码方式:
使用一个函数own,将对象映射到它所拥有的资源;
引入一个逆函数owned-by,以确保每个资源只由一个对象拥有。
对于reference-counted shared ownership,验证器需要确保资源的引用计数与引用该资源的对象数量相匹配。验证器使用以下编码方式:
对于每个资源r,引入一个排列函数π,以对对象进行排序,使只有前refcnt(r)个对象引用资源r。
确保π是一个有效的排列,即存在逆函数π⁻¹。
总结
- 设计了有限的内核接口,避免了无界的循环和递归,以适应SMT求解器的自动化验证。
- 使用硬件虚拟化技术简化了内核地址空间的管理,避免了对复杂的虚拟地址转换的建模。
- 在LLVM IR而不是源代码级别进行验证,减少了对C语言语义的建模工作。
- 提出了两级规范,包括状态机规范和更抽象的声明式规范,可以增强对规范正确性的信心。
- 使用SMT求解器Z3实现了对内核的自动化验证,包括验证实现满足规范和验证规范的一致性。